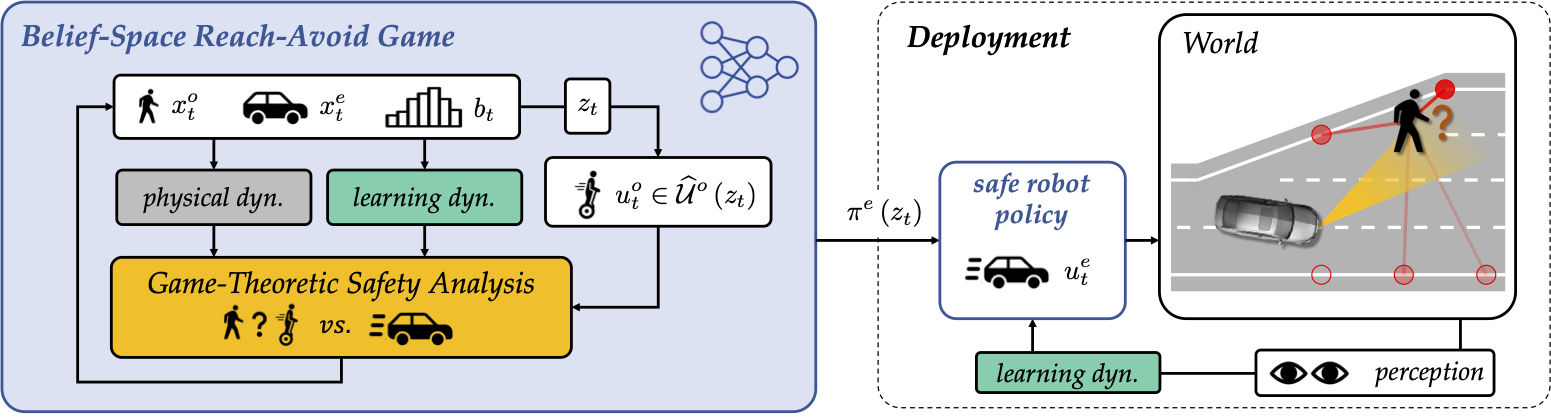
One of the outstanding challenges for the widespread deployment of robotic systems like autonomous
vehicles is ensuring safe
interaction with humans without sacrificing efficiency. Existing safety analysis methods often neglect the
robot's ability to learn and adapt at runtime, leading to overly conservative behavior.
This paper proposes a new closed-loop paradigm for synthesizing safe control policies that explicitly account
for the system's evolving uncertainty under possible future scenarios.
The formulation reasons jointly about the physical dynamics and the robot's learning algorithm, which updates
its internal belief over time.
We leverage adversarial deep reinforcement learning (RL) for scaling to high dimensions, enabling tractable
safety analysis even for implicit learning dynamics induced by state-of-the-art prediction models.
We demonstrate our framework's ability to work with both Bayesian belief propagation and the implicit learning
induced by a large pre-trained neural trajectory predictor.
Method Overview
We pose a Hamilton-Jacobi-Isaacs (HJI) reachability problem that reasons jointly between the physical dynamics
and robot’s learning algorithm to account for how the robot’s belief will evolve and trigger adaptations in its
safe control policy during runtime.
Our problem formulation is amenable to both explicit (e.g., Bayesian updates) and implicit (e.g.,
pretrained motion predictors) belief dynamics. Our approach scales to high dimensions when approximately
computing the solution to the belief-space HJI equation with adversarial reinforcement learning . Our case
studies show the efficacy of our approach for scenarios with an 8D physical state and 192D belief state.
Case Study
When robots are deployed in the real world, there is a large source of uncertainty that cannot be addressed
before deployment. In the below example, the robot is uncertain about whether the human is a pedestrian or
riding a segway (i.e., uncertainty in the human’s dynamics). Furthermore, the robot is also uncertain about the
human's goal point. Our method enables the robot to leverage the information it will receive in the
future to continually update its belief and plan safely.
Comparison to Baselines
We compared an exact dynamic programming solution of our belief-space HJI equation against 3 baselines in 1000
randomized trials with different initial states and opponent types. These trials empirically show that our
method maintains the rigorous safety guarantees of the robust method (always safeguards against all hypotheses),
while maintaining similar performance to an optimistic maximum a posteriori baseline. Our method outperforms the
contingency planning baseline in both safety and performance metrics.
Above, we show a scenario where the ego agent (orange) uses Motion
Transformer (MTR) as the belief dynamics and the policy is computed using adversarial reinforcement
learning. We compared our Deception Game method against an ILQR and robust baseline against an adversarial and
deceptive human. The ILQR baseline, which replanned according to the current MTR predictions, could not account
for how an adversarial human can influence the robot’s future predictions, causing it to fail all trials. In
contrast, our method was able to account for the future evolutions of the robot’s belief, allowing it to act
less conservatively than the robust baseline while still remaining safe.
Hypothesis Recovery
Compared to contingency planning baselines, which permanently discard hypotheses if the robot's belief in that
hypothesis falls below a threshold, our policy enables the robot to safeguard against currently inactive
hypothesis may become sufficiently likely in the future as a consequence of our Hamilton-Jacobi
reachability formulation of the Deception Game.
In the above video, the robot has a strong prior for an incorrect human goal. As the scenario
evolves, our Deception Game method is able to recover initially unlikely hypothesis to safely navigate around an
adversarial and deceptive human. In contrast, the MAP and Contingency baselines incur a safety violation and the
robust baseline is unable to progress along the lane within 10 seconds.
Multi-agent Safety
We also show that our method is still effective in driving scenarios where there are multiple agent by applying
our safety controller pairwise between the ego vehicle and the nearest agent.